Timeseries classification from scratch
Source:vignettes/examples/timeseries/timeseries_classification_from_scratch.Rmd
timeseries_classification_from_scratch.RmdIntroduction
This example shows how to do timeseries classification from scratch, starting from raw CSV timeseries files on disk. We demonstrate the workflow on the FordA dataset from the UCR/UEA archive.
Setup
library(keras3)
use_backend("jax")Load the data: the FordA dataset
Dataset description
The dataset we are using here is called FordA. The data comes from the UCR archive. The dataset contains 3601 training instances and another 1320 testing instances. Each timeseries corresponds to a measurement of engine noise captured by a motor sensor. For this task, the goal is to automatically detect the presence of a specific issue with the engine. The problem is a balanced binary classification task. The full description of this dataset can be found here.
Read the TSV data
We will use the FordA_TRAIN file for training and the
FordA_TEST file for testing. The simplicity of this dataset
allows us to demonstrate effectively how to use ConvNets for timeseries
classification. In this file, the first column corresponds to the
label.
get_data <- function(path) {
if(path |> startsWith("https://"))
path <- get_file(origin = path) # cache file locally
data <- readr::read_tsv(
path, col_names = FALSE,
# Each row is: one integer (the label),
# followed by 500 doubles (the timeseries)
col_types = paste0("i", strrep("d", 500))
)
y <- as.matrix(data[[1]])
x <- as.matrix(data[,-1])
dimnames(x) <- dimnames(y) <- NULL
list(x, y)
}
root_url <- "https://raw.githubusercontent.com/hfawaz/cd-diagram/master/FordA/"
c(x_train, y_train) %<-% get_data(paste0(root_url, "FordA_TRAIN.tsv"))
c(x_test, y_test) %<-% get_data(paste0(root_url, "FordA_TEST.tsv"))
str(keras3:::named_list(
x_train, y_train,
x_test, y_test
))## List of 4
## $ x_train: num [1:3601, 1:500] -0.797 0.805 0.728 -0.234 -0.171 ...
## $ y_train: int [1:3601, 1] -1 1 -1 -1 -1 1 1 1 1 1 ...
## $ x_test : num [1:1320, 1:500] -0.14 0.334 0.717 1.24 -1.159 ...
## $ y_test : int [1:1320, 1] -1 -1 -1 1 -1 1 -1 -1 1 1 ...Visualize the data
Here we visualize one timeseries example for each class in the dataset.
plot(NULL, main = "Timeseries Data",
xlab = "Timepoints", ylab = "Values",
xlim = c(1, ncol(x_test)),
ylim = range(x_test))
grid()
lines(x_test[match(-1, y_test), ], col = "blue")
lines(x_test[match( 1, y_test), ], col = "red")
legend("topright", legend=c("label -1", "label 1"), col=c("blue", "red"), lty=1)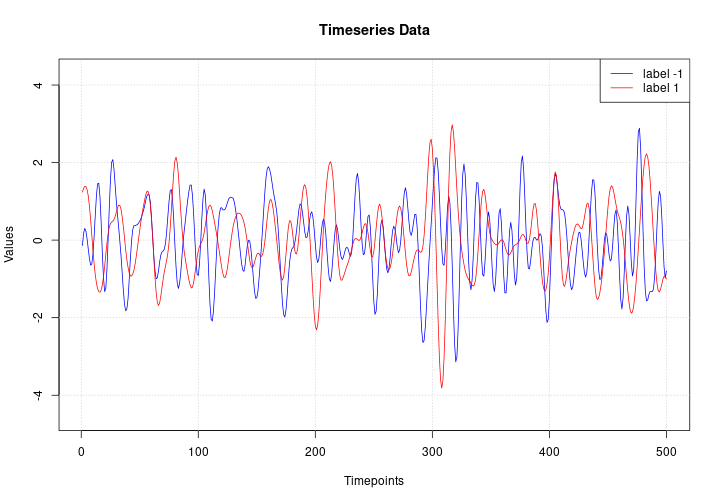
Standardize the data
Our timeseries are already in a single length (500). However, their values are usually in various ranges. This is not ideal for a neural network; in general we should seek to make the input values normalized. For this specific dataset, the data is already z-normalized: each timeseries sample has a mean equal to zero and a standard deviation equal to one. This type of normalization is very common for timeseries classification problems, see Bagnall et al. (2016).
Note that the timeseries data used here are univariate, meaning we only have one channel per timeseries example. We will therefore transform the timeseries into a multivariate one with one channel using a simple reshaping via numpy. This will allow us to construct a model that is easily applicable to multivariate time series.
Finally, in order to use
sparse_categorical_crossentropy, we will have to count the
number of classes beforehand.
Now we shuffle the training set because we will be using the
validation_split option later when training.
c(x_train, y_train) %<-% listarrays::shuffle_rows(x_train, y_train)
# idx <- sample.int(nrow(x_train))
# x_train %<>% .[idx,, ,drop = FALSE]
# y_train %<>% .[idx, ,drop = FALSE]Standardize the labels to positive integers. The expected labels will then be 0 and 1.
y_train[y_train == -1L] <- 0L
y_test[y_test == -1L] <- 0LBuild a model
We build a Fully Convolutional Neural Network originally proposed in this paper. The implementation is based on the TF 2 version provided here. The following hyperparameters (kernel_size, filters, the usage of BatchNorm) were found via random search using KerasTuner.
make_model <- function(input_shape) {
inputs <- keras_input(input_shape)
outputs <- inputs |>
# conv1
layer_conv_1d(filters = 64, kernel_size = 3, padding = "same") |>
layer_batch_normalization() |>
layer_activation_relu() |>
# conv2
layer_conv_1d(filters = 64, kernel_size = 3, padding = "same") |>
layer_batch_normalization() |>
layer_activation_relu() |>
# conv3
layer_conv_1d(filters = 64, kernel_size = 3, padding = "same") |>
layer_batch_normalization() |>
layer_activation_relu() |>
# pooling
layer_global_average_pooling_1d() |>
# final output
layer_dense(num_classes, activation = "softmax")
keras_model(inputs, outputs)
}
model <- make_model(input_shape = dim(x_train)[-1])
model## Model: "functional_1"
## ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━┓
## ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Trai… ┃
## ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━┩
## │ input_layer (InputLayer) │ (None, 500, 1) │ 0 │ - │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ conv1d_2 (Conv1D) │ (None, 500, 64) │ 256 │ Y │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ batch_normalization_2 │ (None, 500, 64) │ 256 │ Y │
## │ (BatchNormalization) │ │ │ │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ re_lu_2 (ReLU) │ (None, 500, 64) │ 0 │ - │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ conv1d_1 (Conv1D) │ (None, 500, 64) │ 12,352 │ Y │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ batch_normalization_1 │ (None, 500, 64) │ 256 │ Y │
## │ (BatchNormalization) │ │ │ │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ re_lu_1 (ReLU) │ (None, 500, 64) │ 0 │ - │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ conv1d (Conv1D) │ (None, 500, 64) │ 12,352 │ Y │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ batch_normalization │ (None, 500, 64) │ 256 │ Y │
## │ (BatchNormalization) │ │ │ │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ re_lu (ReLU) │ (None, 500, 64) │ 0 │ - │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ global_average_pooling1d │ (None, 64) │ 0 │ - │
## │ (GlobalAveragePooling1D) │ │ │ │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ dense (Dense) │ (None, 2) │ 130 │ Y │
## └─────────────────────────────┴───────────────────────┴────────────┴───────┘
## Total params: 25,858 (101.01 KB)
## Trainable params: 25,474 (99.51 KB)
## Non-trainable params: 384 (1.50 KB)
plot(model, show_shapes = TRUE)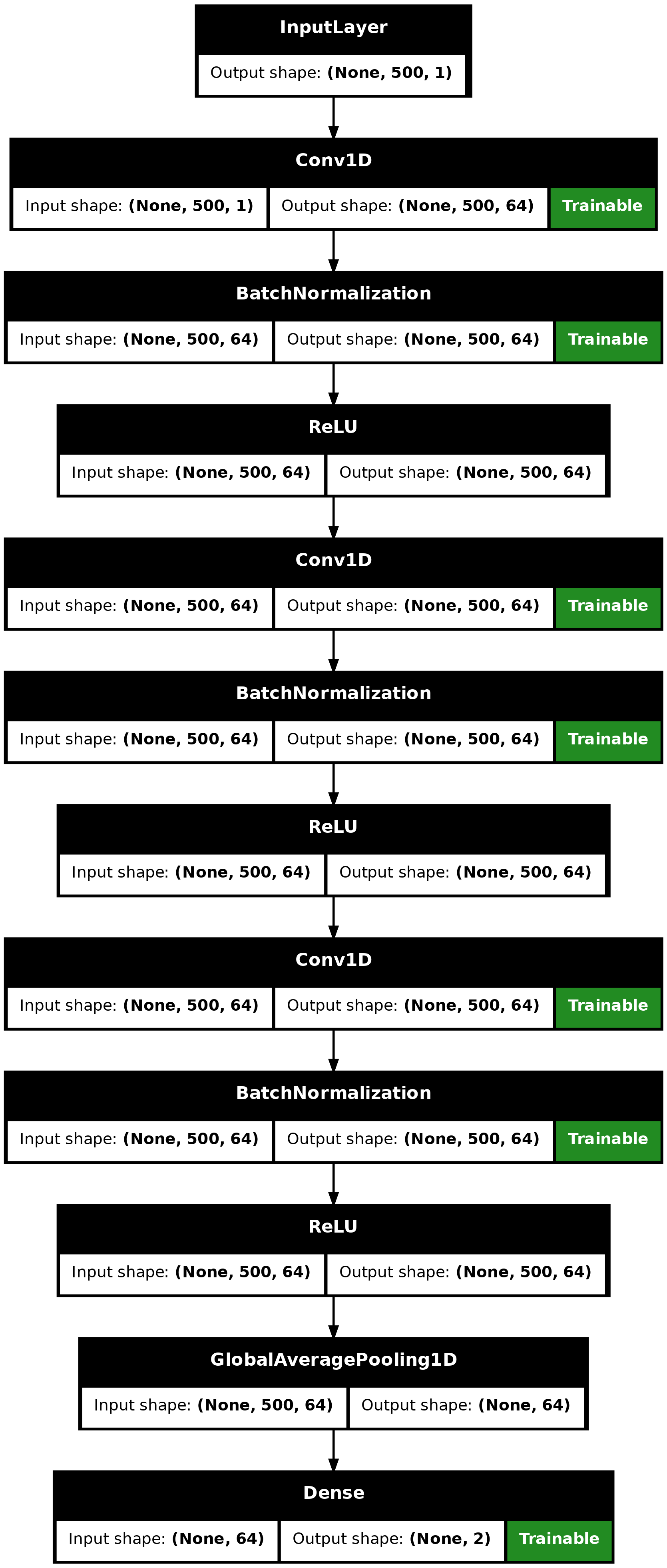
plot of chunk unnamed-chunk-9
Train the model
epochs <- 500
batch_size <- 32
callbacks <- c(
callback_model_checkpoint(
"best_model.keras", save_best_only = TRUE,
monitor = "val_loss"
),
callback_reduce_lr_on_plateau(
monitor = "val_loss", factor = 0.5,
patience = 20, min_lr = 0.0001
),
callback_early_stopping(
monitor = "val_loss", patience = 50,
verbose = 1
)
)
model |> compile(
optimizer = "adam",
loss = "sparse_categorical_crossentropy",
metrics = "sparse_categorical_accuracy"
)
history <- model |> fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
callbacks = callbacks,
validation_split = 0.2
)## Epoch 1/500
## 90/90 - 2s - 24ms/step - loss: 0.5709 - sparse_categorical_accuracy: 0.6941 - val_loss: 0.7543 - val_sparse_categorical_accuracy: 0.4896 - learning_rate: 0.0010
## Epoch 2/500
## 90/90 - 1s - 7ms/step - loss: 0.4992 - sparse_categorical_accuracy: 0.7500 - val_loss: 0.8096 - val_sparse_categorical_accuracy: 0.4896 - learning_rate: 0.0010
## Epoch 3/500
## 90/90 - 0s - 2ms/step - loss: 0.4618 - sparse_categorical_accuracy: 0.7656 - val_loss: 0.7139 - val_sparse_categorical_accuracy: 0.4910 - learning_rate: 0.0010
## Epoch 4/500
## 90/90 - 0s - 2ms/step - loss: 0.4223 - sparse_categorical_accuracy: 0.7878 - val_loss: 0.6720 - val_sparse_categorical_accuracy: 0.4965 - learning_rate: 0.0010
## Epoch 5/500
## 90/90 - 0s - 2ms/step - loss: 0.4231 - sparse_categorical_accuracy: 0.7812 - val_loss: 0.5293 - val_sparse_categorical_accuracy: 0.8100 - learning_rate: 0.0010
## Epoch 6/500
## 90/90 - 0s - 2ms/step - loss: 0.4041 - sparse_categorical_accuracy: 0.8003 - val_loss: 0.4510 - val_sparse_categorical_accuracy: 0.8183 - learning_rate: 0.0010
## Epoch 7/500
## 90/90 - 0s - 1ms/step - loss: 0.4001 - sparse_categorical_accuracy: 0.8014 - val_loss: 0.6951 - val_sparse_categorical_accuracy: 0.6755 - learning_rate: 0.0010
## Epoch 8/500
## 90/90 - 0s - 2ms/step - loss: 0.3895 - sparse_categorical_accuracy: 0.8049 - val_loss: 0.4036 - val_sparse_categorical_accuracy: 0.7989 - learning_rate: 0.0010
## Epoch 9/500
## 90/90 - 0s - 2ms/step - loss: 0.3830 - sparse_categorical_accuracy: 0.8194 - val_loss: 0.3749 - val_sparse_categorical_accuracy: 0.8252 - learning_rate: 0.0010
## Epoch 10/500
## 90/90 - 0s - 1ms/step - loss: 0.3810 - sparse_categorical_accuracy: 0.8128 - val_loss: 0.4175 - val_sparse_categorical_accuracy: 0.7892 - learning_rate: 0.0010
## Epoch 11/500
## 90/90 - 0s - 2ms/step - loss: 0.3736 - sparse_categorical_accuracy: 0.8174 - val_loss: 0.3704 - val_sparse_categorical_accuracy: 0.8169 - learning_rate: 0.0010
## Epoch 12/500
## 90/90 - 0s - 1ms/step - loss: 0.3646 - sparse_categorical_accuracy: 0.8264 - val_loss: 0.3777 - val_sparse_categorical_accuracy: 0.8239 - learning_rate: 0.0010
## Epoch 13/500
## 90/90 - 0s - 2ms/step - loss: 0.3555 - sparse_categorical_accuracy: 0.8361 - val_loss: 0.4207 - val_sparse_categorical_accuracy: 0.7822 - learning_rate: 0.0010
## Epoch 14/500
## 90/90 - 0s - 2ms/step - loss: 0.3581 - sparse_categorical_accuracy: 0.8278 - val_loss: 0.3698 - val_sparse_categorical_accuracy: 0.8141 - learning_rate: 0.0010
## Epoch 15/500
## 90/90 - 0s - 2ms/step - loss: 0.3416 - sparse_categorical_accuracy: 0.8458 - val_loss: 0.4507 - val_sparse_categorical_accuracy: 0.7587 - learning_rate: 0.0010
## Epoch 16/500
## 90/90 - 0s - 2ms/step - loss: 0.3417 - sparse_categorical_accuracy: 0.8410 - val_loss: 0.3326 - val_sparse_categorical_accuracy: 0.8460 - learning_rate: 0.0010
## Epoch 17/500
## 90/90 - 0s - 1ms/step - loss: 0.3313 - sparse_categorical_accuracy: 0.8462 - val_loss: 0.3678 - val_sparse_categorical_accuracy: 0.8211 - learning_rate: 0.0010
## Epoch 18/500
## 90/90 - 0s - 2ms/step - loss: 0.3218 - sparse_categorical_accuracy: 0.8552 - val_loss: 0.3233 - val_sparse_categorical_accuracy: 0.8585 - learning_rate: 0.0010
## Epoch 19/500
## 90/90 - 0s - 1ms/step - loss: 0.3171 - sparse_categorical_accuracy: 0.8670 - val_loss: 0.3378 - val_sparse_categorical_accuracy: 0.8488 - learning_rate: 0.0010
## Epoch 20/500
## 90/90 - 0s - 1ms/step - loss: 0.3178 - sparse_categorical_accuracy: 0.8580 - val_loss: 0.6069 - val_sparse_categorical_accuracy: 0.6907 - learning_rate: 0.0010
## Epoch 21/500
## 90/90 - 0s - 1ms/step - loss: 0.2959 - sparse_categorical_accuracy: 0.8774 - val_loss: 0.3907 - val_sparse_categorical_accuracy: 0.7989 - learning_rate: 0.0010
## Epoch 22/500
## 90/90 - 0s - 1ms/step - loss: 0.3052 - sparse_categorical_accuracy: 0.8642 - val_loss: 0.3707 - val_sparse_categorical_accuracy: 0.8308 - learning_rate: 0.0010
## Epoch 23/500
## 90/90 - 0s - 2ms/step - loss: 0.2905 - sparse_categorical_accuracy: 0.8837 - val_loss: 0.2981 - val_sparse_categorical_accuracy: 0.8752 - learning_rate: 0.0010
## Epoch 24/500
## 90/90 - 0s - 1ms/step - loss: 0.2874 - sparse_categorical_accuracy: 0.8778 - val_loss: 0.4721 - val_sparse_categorical_accuracy: 0.7462 - learning_rate: 0.0010
## Epoch 25/500
## 90/90 - 0s - 2ms/step - loss: 0.2829 - sparse_categorical_accuracy: 0.8781 - val_loss: 0.4335 - val_sparse_categorical_accuracy: 0.7753 - learning_rate: 0.0010
## Epoch 26/500
## 90/90 - 0s - 1ms/step - loss: 0.2998 - sparse_categorical_accuracy: 0.8677 - val_loss: 0.3029 - val_sparse_categorical_accuracy: 0.8585 - learning_rate: 0.0010
## Epoch 27/500
## 90/90 - 0s - 2ms/step - loss: 0.2709 - sparse_categorical_accuracy: 0.8906 - val_loss: 0.2847 - val_sparse_categorical_accuracy: 0.8877 - learning_rate: 0.0010
## Epoch 28/500
## 90/90 - 0s - 1ms/step - loss: 0.2901 - sparse_categorical_accuracy: 0.8753 - val_loss: 0.3450 - val_sparse_categorical_accuracy: 0.8460 - learning_rate: 0.0010
## Epoch 29/500
## 90/90 - 0s - 1ms/step - loss: 0.2696 - sparse_categorical_accuracy: 0.8802 - val_loss: 0.9118 - val_sparse_categorical_accuracy: 0.6172 - learning_rate: 0.0010
## Epoch 30/500
## 90/90 - 0s - 1ms/step - loss: 0.2726 - sparse_categorical_accuracy: 0.8833 - val_loss: 0.2870 - val_sparse_categorical_accuracy: 0.8849 - learning_rate: 0.0010
## Epoch 31/500
## 90/90 - 0s - 1ms/step - loss: 0.2735 - sparse_categorical_accuracy: 0.8865 - val_loss: 0.2827 - val_sparse_categorical_accuracy: 0.8904 - learning_rate: 0.0010
## Epoch 32/500
## 90/90 - 0s - 2ms/step - loss: 0.2692 - sparse_categorical_accuracy: 0.8865 - val_loss: 0.2814 - val_sparse_categorical_accuracy: 0.8849 - learning_rate: 0.0010
## Epoch 33/500
## 90/90 - 0s - 1ms/step - loss: 0.2564 - sparse_categorical_accuracy: 0.8941 - val_loss: 0.6602 - val_sparse_categorical_accuracy: 0.7143 - learning_rate: 0.0010
## Epoch 34/500
## 90/90 - 0s - 1ms/step - loss: 0.2475 - sparse_categorical_accuracy: 0.8969 - val_loss: 0.3530 - val_sparse_categorical_accuracy: 0.8294 - learning_rate: 0.0010
## Epoch 35/500
## 90/90 - 0s - 1ms/step - loss: 0.2652 - sparse_categorical_accuracy: 0.8892 - val_loss: 0.3189 - val_sparse_categorical_accuracy: 0.8322 - learning_rate: 0.0010
## Epoch 36/500
## 90/90 - 0s - 1ms/step - loss: 0.2551 - sparse_categorical_accuracy: 0.8941 - val_loss: 0.4109 - val_sparse_categorical_accuracy: 0.7906 - learning_rate: 0.0010
## Epoch 37/500
## 90/90 - 0s - 1ms/step - loss: 0.2532 - sparse_categorical_accuracy: 0.8965 - val_loss: 0.7285 - val_sparse_categorical_accuracy: 0.7129 - learning_rate: 0.0010
## Epoch 38/500
## 90/90 - 0s - 1ms/step - loss: 0.2607 - sparse_categorical_accuracy: 0.8965 - val_loss: 1.1758 - val_sparse_categorical_accuracy: 0.6963 - learning_rate: 0.0010
## Epoch 39/500
## 90/90 - 0s - 1ms/step - loss: 0.2531 - sparse_categorical_accuracy: 0.8983 - val_loss: 0.2975 - val_sparse_categorical_accuracy: 0.8613 - learning_rate: 0.0010
## Epoch 40/500
## 90/90 - 0s - 1ms/step - loss: 0.2529 - sparse_categorical_accuracy: 0.8927 - val_loss: 0.4194 - val_sparse_categorical_accuracy: 0.8155 - learning_rate: 0.0010
## Epoch 41/500
## 90/90 - 0s - 1ms/step - loss: 0.2363 - sparse_categorical_accuracy: 0.9042 - val_loss: 0.3802 - val_sparse_categorical_accuracy: 0.8100 - learning_rate: 0.0010
## Epoch 42/500
## 90/90 - 0s - 1ms/step - loss: 0.2336 - sparse_categorical_accuracy: 0.9094 - val_loss: 0.7136 - val_sparse_categorical_accuracy: 0.7171 - learning_rate: 0.0010
## Epoch 43/500
## 90/90 - 0s - 2ms/step - loss: 0.2435 - sparse_categorical_accuracy: 0.9007 - val_loss: 0.2766 - val_sparse_categorical_accuracy: 0.8682 - learning_rate: 0.0010
## Epoch 44/500
## 90/90 - 0s - 1ms/step - loss: 0.2377 - sparse_categorical_accuracy: 0.9024 - val_loss: 0.5334 - val_sparse_categorical_accuracy: 0.7490 - learning_rate: 0.0010
## Epoch 45/500
## 90/90 - 0s - 2ms/step - loss: 0.2430 - sparse_categorical_accuracy: 0.9021 - val_loss: 0.2486 - val_sparse_categorical_accuracy: 0.8890 - learning_rate: 0.0010
## Epoch 46/500
## 90/90 - 0s - 1ms/step - loss: 0.2421 - sparse_categorical_accuracy: 0.8969 - val_loss: 0.4141 - val_sparse_categorical_accuracy: 0.8100 - learning_rate: 0.0010
## Epoch 47/500
## 90/90 - 0s - 1ms/step - loss: 0.2283 - sparse_categorical_accuracy: 0.9062 - val_loss: 1.3193 - val_sparse_categorical_accuracy: 0.5992 - learning_rate: 0.0010
## Epoch 48/500
## 90/90 - 0s - 2ms/step - loss: 0.2267 - sparse_categorical_accuracy: 0.9066 - val_loss: 0.2447 - val_sparse_categorical_accuracy: 0.9085 - learning_rate: 0.0010
## Epoch 49/500
## 90/90 - 0s - 1ms/step - loss: 0.2248 - sparse_categorical_accuracy: 0.9052 - val_loss: 0.3022 - val_sparse_categorical_accuracy: 0.8641 - learning_rate: 0.0010
## Epoch 50/500
## 90/90 - 0s - 1ms/step - loss: 0.2275 - sparse_categorical_accuracy: 0.9108 - val_loss: 1.0244 - val_sparse_categorical_accuracy: 0.6130 - learning_rate: 0.0010
## Epoch 51/500
## 90/90 - 0s - 1ms/step - loss: 0.2288 - sparse_categorical_accuracy: 0.9090 - val_loss: 0.4970 - val_sparse_categorical_accuracy: 0.7559 - learning_rate: 0.0010
## Epoch 52/500
## 90/90 - 0s - 1ms/step - loss: 0.2224 - sparse_categorical_accuracy: 0.9101 - val_loss: 0.3418 - val_sparse_categorical_accuracy: 0.8516 - learning_rate: 0.0010
## Epoch 53/500
## 90/90 - 0s - 1ms/step - loss: 0.2167 - sparse_categorical_accuracy: 0.9149 - val_loss: 0.3619 - val_sparse_categorical_accuracy: 0.8017 - learning_rate: 0.0010
## Epoch 54/500
## 90/90 - 0s - 1ms/step - loss: 0.2184 - sparse_categorical_accuracy: 0.9062 - val_loss: 0.2868 - val_sparse_categorical_accuracy: 0.8641 - learning_rate: 0.0010
## Epoch 55/500
## 90/90 - 0s - 1ms/step - loss: 0.2104 - sparse_categorical_accuracy: 0.9135 - val_loss: 1.5653 - val_sparse_categorical_accuracy: 0.6227 - learning_rate: 0.0010
## Epoch 56/500
## 90/90 - 0s - 1ms/step - loss: 0.2065 - sparse_categorical_accuracy: 0.9229 - val_loss: 0.3880 - val_sparse_categorical_accuracy: 0.8322 - learning_rate: 0.0010
## Epoch 57/500
## 90/90 - 0s - 2ms/step - loss: 0.2068 - sparse_categorical_accuracy: 0.9267 - val_loss: 0.2148 - val_sparse_categorical_accuracy: 0.9029 - learning_rate: 0.0010
## Epoch 58/500
## 90/90 - 0s - 1ms/step - loss: 0.1885 - sparse_categorical_accuracy: 0.9302 - val_loss: 0.2319 - val_sparse_categorical_accuracy: 0.9029 - learning_rate: 0.0010
## Epoch 59/500
## 90/90 - 0s - 1ms/step - loss: 0.2110 - sparse_categorical_accuracy: 0.9163 - val_loss: 0.2822 - val_sparse_categorical_accuracy: 0.8863 - learning_rate: 0.0010
## Epoch 60/500
## 90/90 - 0s - 2ms/step - loss: 0.1860 - sparse_categorical_accuracy: 0.9316 - val_loss: 0.2138 - val_sparse_categorical_accuracy: 0.8946 - learning_rate: 0.0010
## Epoch 61/500
## 90/90 - 0s - 1ms/step - loss: 0.1817 - sparse_categorical_accuracy: 0.9347 - val_loss: 1.2721 - val_sparse_categorical_accuracy: 0.6297 - learning_rate: 0.0010
## Epoch 62/500
## 90/90 - 0s - 2ms/step - loss: 0.1767 - sparse_categorical_accuracy: 0.9361 - val_loss: 0.9618 - val_sparse_categorical_accuracy: 0.7115 - learning_rate: 0.0010
## Epoch 63/500
## 90/90 - 0s - 1ms/step - loss: 0.1842 - sparse_categorical_accuracy: 0.9292 - val_loss: 1.5073 - val_sparse_categorical_accuracy: 0.6117 - learning_rate: 0.0010
## Epoch 64/500
## 90/90 - 0s - 1ms/step - loss: 0.1676 - sparse_categorical_accuracy: 0.9410 - val_loss: 0.5498 - val_sparse_categorical_accuracy: 0.7573 - learning_rate: 0.0010
## Epoch 65/500
## 90/90 - 0s - 1ms/step - loss: 0.1531 - sparse_categorical_accuracy: 0.9476 - val_loss: 1.5368 - val_sparse_categorical_accuracy: 0.6671 - learning_rate: 0.0010
## Epoch 66/500
## 90/90 - 0s - 1ms/step - loss: 0.1442 - sparse_categorical_accuracy: 0.9556 - val_loss: 0.5982 - val_sparse_categorical_accuracy: 0.7393 - learning_rate: 0.0010
## Epoch 67/500
## 90/90 - 0s - 2ms/step - loss: 0.1402 - sparse_categorical_accuracy: 0.9576 - val_loss: 3.4153 - val_sparse_categorical_accuracy: 0.5395 - learning_rate: 0.0010
## Epoch 68/500
## 90/90 - 0s - 1ms/step - loss: 0.1411 - sparse_categorical_accuracy: 0.9514 - val_loss: 3.4579 - val_sparse_categorical_accuracy: 0.5603 - learning_rate: 0.0010
## Epoch 69/500
## 90/90 - 0s - 1ms/step - loss: 0.1625 - sparse_categorical_accuracy: 0.9372 - val_loss: 2.7611 - val_sparse_categorical_accuracy: 0.6588 - learning_rate: 0.0010
## Epoch 70/500
## 90/90 - 0s - 2ms/step - loss: 0.1294 - sparse_categorical_accuracy: 0.9594 - val_loss: 0.2107 - val_sparse_categorical_accuracy: 0.9126 - learning_rate: 0.0010
## Epoch 71/500
## 90/90 - 0s - 1ms/step - loss: 0.1240 - sparse_categorical_accuracy: 0.9594 - val_loss: 0.2447 - val_sparse_categorical_accuracy: 0.9015 - learning_rate: 0.0010
## Epoch 72/500
## 90/90 - 0s - 1ms/step - loss: 0.1245 - sparse_categorical_accuracy: 0.9604 - val_loss: 1.2330 - val_sparse_categorical_accuracy: 0.6935 - learning_rate: 0.0010
## Epoch 73/500
## 90/90 - 0s - 1ms/step - loss: 0.1179 - sparse_categorical_accuracy: 0.9622 - val_loss: 0.2634 - val_sparse_categorical_accuracy: 0.9001 - learning_rate: 0.0010
## Epoch 74/500
## 90/90 - 0s - 2ms/step - loss: 0.1154 - sparse_categorical_accuracy: 0.9601 - val_loss: 0.1480 - val_sparse_categorical_accuracy: 0.9431 - learning_rate: 0.0010
## Epoch 75/500
## 90/90 - 0s - 1ms/step - loss: 0.1405 - sparse_categorical_accuracy: 0.9500 - val_loss: 0.1601 - val_sparse_categorical_accuracy: 0.9376 - learning_rate: 0.0010
## Epoch 76/500
## 90/90 - 0s - 1ms/step - loss: 0.1285 - sparse_categorical_accuracy: 0.9569 - val_loss: 0.3239 - val_sparse_categorical_accuracy: 0.8738 - learning_rate: 0.0010
## Epoch 77/500
## 90/90 - 0s - 1ms/step - loss: 0.1132 - sparse_categorical_accuracy: 0.9622 - val_loss: 0.2373 - val_sparse_categorical_accuracy: 0.9209 - learning_rate: 0.0010
## Epoch 78/500
## 90/90 - 0s - 1ms/step - loss: 0.1061 - sparse_categorical_accuracy: 0.9670 - val_loss: 0.1544 - val_sparse_categorical_accuracy: 0.9417 - learning_rate: 0.0010
## Epoch 79/500
## 90/90 - 0s - 1ms/step - loss: 0.1076 - sparse_categorical_accuracy: 0.9642 - val_loss: 0.3019 - val_sparse_categorical_accuracy: 0.8516 - learning_rate: 0.0010
## Epoch 80/500
## 90/90 - 0s - 1ms/step - loss: 0.1076 - sparse_categorical_accuracy: 0.9632 - val_loss: 0.1488 - val_sparse_categorical_accuracy: 0.9376 - learning_rate: 0.0010
## Epoch 81/500
## 90/90 - 0s - 1ms/step - loss: 0.1085 - sparse_categorical_accuracy: 0.9663 - val_loss: 0.8099 - val_sparse_categorical_accuracy: 0.7365 - learning_rate: 0.0010
## Epoch 82/500
## 90/90 - 0s - 2ms/step - loss: 0.0998 - sparse_categorical_accuracy: 0.9677 - val_loss: 0.1340 - val_sparse_categorical_accuracy: 0.9473 - learning_rate: 0.0010
## Epoch 83/500
## 90/90 - 0s - 1ms/step - loss: 0.1080 - sparse_categorical_accuracy: 0.9639 - val_loss: 1.0744 - val_sparse_categorical_accuracy: 0.6768 - learning_rate: 0.0010
## Epoch 84/500
## 90/90 - 0s - 1ms/step - loss: 0.1030 - sparse_categorical_accuracy: 0.9642 - val_loss: 2.1788 - val_sparse_categorical_accuracy: 0.6366 - learning_rate: 0.0010
## Epoch 85/500
## 90/90 - 0s - 1ms/step - loss: 0.1063 - sparse_categorical_accuracy: 0.9639 - val_loss: 0.7455 - val_sparse_categorical_accuracy: 0.7545 - learning_rate: 0.0010
## Epoch 86/500
## 90/90 - 0s - 1ms/step - loss: 0.1047 - sparse_categorical_accuracy: 0.9653 - val_loss: 2.0761 - val_sparse_categorical_accuracy: 0.6782 - learning_rate: 0.0010
## Epoch 87/500
## 90/90 - 0s - 1ms/step - loss: 0.1098 - sparse_categorical_accuracy: 0.9597 - val_loss: 1.7229 - val_sparse_categorical_accuracy: 0.6449 - learning_rate: 0.0010
## Epoch 88/500
## 90/90 - 0s - 1ms/step - loss: 0.1046 - sparse_categorical_accuracy: 0.9656 - val_loss: 0.2215 - val_sparse_categorical_accuracy: 0.9029 - learning_rate: 0.0010
## Epoch 89/500
## 90/90 - 0s - 2ms/step - loss: 0.1012 - sparse_categorical_accuracy: 0.9632 - val_loss: 0.1230 - val_sparse_categorical_accuracy: 0.9501 - learning_rate: 0.0010
## Epoch 90/500
## 90/90 - 0s - 2ms/step - loss: 0.0947 - sparse_categorical_accuracy: 0.9684 - val_loss: 0.1193 - val_sparse_categorical_accuracy: 0.9487 - learning_rate: 0.0010
## Epoch 91/500
## 90/90 - 0s - 1ms/step - loss: 0.1121 - sparse_categorical_accuracy: 0.9622 - val_loss: 0.7555 - val_sparse_categorical_accuracy: 0.7365 - learning_rate: 0.0010
## Epoch 92/500
## 90/90 - 0s - 1ms/step - loss: 0.1030 - sparse_categorical_accuracy: 0.9670 - val_loss: 0.2366 - val_sparse_categorical_accuracy: 0.8988 - learning_rate: 0.0010
## Epoch 93/500
## 90/90 - 0s - 1ms/step - loss: 0.0992 - sparse_categorical_accuracy: 0.9653 - val_loss: 0.2028 - val_sparse_categorical_accuracy: 0.9237 - learning_rate: 0.0010
## Epoch 94/500
## 90/90 - 0s - 2ms/step - loss: 0.0976 - sparse_categorical_accuracy: 0.9677 - val_loss: 0.1130 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 0.0010
## Epoch 95/500
## 90/90 - 0s - 1ms/step - loss: 0.0964 - sparse_categorical_accuracy: 0.9677 - val_loss: 1.5808 - val_sparse_categorical_accuracy: 0.6047 - learning_rate: 0.0010
## Epoch 96/500
## 90/90 - 0s - 1ms/step - loss: 0.1118 - sparse_categorical_accuracy: 0.9590 - val_loss: 0.2294 - val_sparse_categorical_accuracy: 0.9098 - learning_rate: 0.0010
## Epoch 97/500
## 90/90 - 0s - 1ms/step - loss: 0.1082 - sparse_categorical_accuracy: 0.9597 - val_loss: 0.5787 - val_sparse_categorical_accuracy: 0.8031 - learning_rate: 0.0010
## Epoch 98/500
## 90/90 - 0s - 1ms/step - loss: 0.0988 - sparse_categorical_accuracy: 0.9674 - val_loss: 1.4890 - val_sparse_categorical_accuracy: 0.6949 - learning_rate: 0.0010
## Epoch 99/500
## 90/90 - 0s - 1ms/step - loss: 0.0950 - sparse_categorical_accuracy: 0.9684 - val_loss: 0.1659 - val_sparse_categorical_accuracy: 0.9390 - learning_rate: 0.0010
## Epoch 100/500
## 90/90 - 0s - 1ms/step - loss: 0.0936 - sparse_categorical_accuracy: 0.9712 - val_loss: 0.4124 - val_sparse_categorical_accuracy: 0.8613 - learning_rate: 0.0010
## Epoch 101/500
## 90/90 - 0s - 1ms/step - loss: 0.0879 - sparse_categorical_accuracy: 0.9722 - val_loss: 0.3583 - val_sparse_categorical_accuracy: 0.8433 - learning_rate: 0.0010
## Epoch 102/500
## 90/90 - 0s - 1ms/step - loss: 0.0999 - sparse_categorical_accuracy: 0.9681 - val_loss: 0.1288 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 0.0010
## Epoch 103/500
## 90/90 - 0s - 1ms/step - loss: 0.0949 - sparse_categorical_accuracy: 0.9674 - val_loss: 0.2152 - val_sparse_categorical_accuracy: 0.9168 - learning_rate: 0.0010
## Epoch 104/500
## 90/90 - 0s - 1ms/step - loss: 0.0959 - sparse_categorical_accuracy: 0.9705 - val_loss: 4.1192 - val_sparse_categorical_accuracy: 0.5007 - learning_rate: 0.0010
## Epoch 105/500
## 90/90 - 0s - 1ms/step - loss: 0.0982 - sparse_categorical_accuracy: 0.9674 - val_loss: 1.1074 - val_sparse_categorical_accuracy: 0.7254 - learning_rate: 0.0010
## Epoch 106/500
## 90/90 - 0s - 1ms/step - loss: 0.0890 - sparse_categorical_accuracy: 0.9694 - val_loss: 0.5496 - val_sparse_categorical_accuracy: 0.8072 - learning_rate: 0.0010
## Epoch 107/500
## 90/90 - 0s - 1ms/step - loss: 0.0937 - sparse_categorical_accuracy: 0.9653 - val_loss: 0.2136 - val_sparse_categorical_accuracy: 0.9182 - learning_rate: 0.0010
## Epoch 108/500
## 90/90 - 0s - 1ms/step - loss: 0.0885 - sparse_categorical_accuracy: 0.9712 - val_loss: 1.9147 - val_sparse_categorical_accuracy: 0.6893 - learning_rate: 0.0010
## Epoch 109/500
## 90/90 - 0s - 1ms/step - loss: 0.0921 - sparse_categorical_accuracy: 0.9729 - val_loss: 0.1533 - val_sparse_categorical_accuracy: 0.9320 - learning_rate: 0.0010
## Epoch 110/500
## 90/90 - 0s - 1ms/step - loss: 0.0954 - sparse_categorical_accuracy: 0.9667 - val_loss: 0.1350 - val_sparse_categorical_accuracy: 0.9501 - learning_rate: 0.0010
## Epoch 111/500
## 90/90 - 0s - 1ms/step - loss: 0.0847 - sparse_categorical_accuracy: 0.9705 - val_loss: 0.1846 - val_sparse_categorical_accuracy: 0.9376 - learning_rate: 0.0010
## Epoch 112/500
## 90/90 - 0s - 1ms/step - loss: 0.0863 - sparse_categorical_accuracy: 0.9705 - val_loss: 0.3858 - val_sparse_categorical_accuracy: 0.8558 - learning_rate: 0.0010
## Epoch 113/500
## 90/90 - 0s - 1ms/step - loss: 0.0847 - sparse_categorical_accuracy: 0.9691 - val_loss: 1.0586 - val_sparse_categorical_accuracy: 0.7226 - learning_rate: 0.0010
## Epoch 114/500
## 90/90 - 0s - 1ms/step - loss: 0.0989 - sparse_categorical_accuracy: 0.9670 - val_loss: 0.4047 - val_sparse_categorical_accuracy: 0.8405 - learning_rate: 0.0010
## Epoch 115/500
## 90/90 - 1s - 6ms/step - loss: 0.0732 - sparse_categorical_accuracy: 0.9771 - val_loss: 0.1151 - val_sparse_categorical_accuracy: 0.9570 - learning_rate: 5.0000e-04
## Epoch 116/500
## 90/90 - 0s - 1ms/step - loss: 0.0785 - sparse_categorical_accuracy: 0.9747 - val_loss: 0.1906 - val_sparse_categorical_accuracy: 0.9376 - learning_rate: 5.0000e-04
## Epoch 117/500
## 90/90 - 0s - 1ms/step - loss: 0.0725 - sparse_categorical_accuracy: 0.9750 - val_loss: 0.1588 - val_sparse_categorical_accuracy: 0.9445 - learning_rate: 5.0000e-04
## Epoch 118/500
## 90/90 - 0s - 1ms/step - loss: 0.0765 - sparse_categorical_accuracy: 0.9743 - val_loss: 0.2465 - val_sparse_categorical_accuracy: 0.9182 - learning_rate: 5.0000e-04
## Epoch 119/500
## 90/90 - 0s - 2ms/step - loss: 0.0767 - sparse_categorical_accuracy: 0.9760 - val_loss: 0.1098 - val_sparse_categorical_accuracy: 0.9570 - learning_rate: 5.0000e-04
## Epoch 120/500
## 90/90 - 0s - 1ms/step - loss: 0.0790 - sparse_categorical_accuracy: 0.9750 - val_loss: 0.1303 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 5.0000e-04
## Epoch 121/500
## 90/90 - 0s - 1ms/step - loss: 0.0775 - sparse_categorical_accuracy: 0.9767 - val_loss: 0.2520 - val_sparse_categorical_accuracy: 0.9043 - learning_rate: 5.0000e-04
## Epoch 122/500
## 90/90 - 0s - 1ms/step - loss: 0.0797 - sparse_categorical_accuracy: 0.9722 - val_loss: 0.1654 - val_sparse_categorical_accuracy: 0.9362 - learning_rate: 5.0000e-04
## Epoch 123/500
## 90/90 - 0s - 1ms/step - loss: 0.0737 - sparse_categorical_accuracy: 0.9767 - val_loss: 0.1159 - val_sparse_categorical_accuracy: 0.9584 - learning_rate: 5.0000e-04
## Epoch 124/500
## 90/90 - 0s - 1ms/step - loss: 0.0799 - sparse_categorical_accuracy: 0.9698 - val_loss: 0.1663 - val_sparse_categorical_accuracy: 0.9265 - learning_rate: 5.0000e-04
## Epoch 125/500
## 90/90 - 0s - 2ms/step - loss: 0.0789 - sparse_categorical_accuracy: 0.9757 - val_loss: 0.1079 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 5.0000e-04
## Epoch 126/500
## 90/90 - 0s - 1ms/step - loss: 0.0722 - sparse_categorical_accuracy: 0.9774 - val_loss: 0.1269 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 5.0000e-04
## Epoch 127/500
## 90/90 - 0s - 1ms/step - loss: 0.0776 - sparse_categorical_accuracy: 0.9767 - val_loss: 0.1643 - val_sparse_categorical_accuracy: 0.9362 - learning_rate: 5.0000e-04
## Epoch 128/500
## 90/90 - 0s - 1ms/step - loss: 0.0787 - sparse_categorical_accuracy: 0.9743 - val_loss: 0.1262 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 5.0000e-04
## Epoch 129/500
## 90/90 - 0s - 1ms/step - loss: 0.0734 - sparse_categorical_accuracy: 0.9764 - val_loss: 0.1223 - val_sparse_categorical_accuracy: 0.9584 - learning_rate: 5.0000e-04
## Epoch 130/500
## 90/90 - 0s - 1ms/step - loss: 0.0829 - sparse_categorical_accuracy: 0.9729 - val_loss: 0.1032 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 5.0000e-04
## Epoch 131/500
## 90/90 - 0s - 1ms/step - loss: 0.0702 - sparse_categorical_accuracy: 0.9792 - val_loss: 0.2322 - val_sparse_categorical_accuracy: 0.9043 - learning_rate: 5.0000e-04
## Epoch 132/500
## 90/90 - 0s - 1ms/step - loss: 0.0691 - sparse_categorical_accuracy: 0.9778 - val_loss: 0.2449 - val_sparse_categorical_accuracy: 0.9085 - learning_rate: 5.0000e-04
## Epoch 133/500
## 90/90 - 0s - 1ms/step - loss: 0.0678 - sparse_categorical_accuracy: 0.9781 - val_loss: 0.1262 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 5.0000e-04
## Epoch 134/500
## 90/90 - 0s - 1ms/step - loss: 0.0730 - sparse_categorical_accuracy: 0.9760 - val_loss: 0.2207 - val_sparse_categorical_accuracy: 0.9251 - learning_rate: 5.0000e-04
## Epoch 135/500
## 90/90 - 0s - 1ms/step - loss: 0.0730 - sparse_categorical_accuracy: 0.9764 - val_loss: 0.1704 - val_sparse_categorical_accuracy: 0.9404 - learning_rate: 5.0000e-04
## Epoch 136/500
## 90/90 - 0s - 1ms/step - loss: 0.0745 - sparse_categorical_accuracy: 0.9708 - val_loss: 0.2879 - val_sparse_categorical_accuracy: 0.9001 - learning_rate: 5.0000e-04
## Epoch 137/500
## 90/90 - 0s - 2ms/step - loss: 0.0776 - sparse_categorical_accuracy: 0.9753 - val_loss: 0.2103 - val_sparse_categorical_accuracy: 0.9057 - learning_rate: 5.0000e-04
## Epoch 138/500
## 90/90 - 0s - 1ms/step - loss: 0.0737 - sparse_categorical_accuracy: 0.9757 - val_loss: 0.1081 - val_sparse_categorical_accuracy: 0.9570 - learning_rate: 5.0000e-04
## Epoch 139/500
## 90/90 - 0s - 1ms/step - loss: 0.0839 - sparse_categorical_accuracy: 0.9736 - val_loss: 0.1782 - val_sparse_categorical_accuracy: 0.9362 - learning_rate: 5.0000e-04
## Epoch 140/500
## 90/90 - 0s - 1ms/step - loss: 0.0671 - sparse_categorical_accuracy: 0.9806 - val_loss: 0.1611 - val_sparse_categorical_accuracy: 0.9445 - learning_rate: 5.0000e-04
## Epoch 141/500
## 90/90 - 0s - 1ms/step - loss: 0.0697 - sparse_categorical_accuracy: 0.9764 - val_loss: 0.1223 - val_sparse_categorical_accuracy: 0.9459 - learning_rate: 5.0000e-04
## Epoch 142/500
## 90/90 - 0s - 1ms/step - loss: 0.0654 - sparse_categorical_accuracy: 0.9830 - val_loss: 0.1042 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 5.0000e-04
## Epoch 143/500
## 90/90 - 0s - 1ms/step - loss: 0.0728 - sparse_categorical_accuracy: 0.9747 - val_loss: 0.3114 - val_sparse_categorical_accuracy: 0.8877 - learning_rate: 5.0000e-04
## Epoch 144/500
## 90/90 - 0s - 1ms/step - loss: 0.0661 - sparse_categorical_accuracy: 0.9792 - val_loss: 0.1203 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 5.0000e-04
## Epoch 145/500
## 90/90 - 0s - 1ms/step - loss: 0.0685 - sparse_categorical_accuracy: 0.9792 - val_loss: 0.1106 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 5.0000e-04
## Epoch 146/500
## 90/90 - 0s - 1ms/step - loss: 0.0696 - sparse_categorical_accuracy: 0.9771 - val_loss: 0.1181 - val_sparse_categorical_accuracy: 0.9515 - learning_rate: 5.0000e-04
## Epoch 147/500
## 90/90 - 0s - 1ms/step - loss: 0.0726 - sparse_categorical_accuracy: 0.9785 - val_loss: 0.2149 - val_sparse_categorical_accuracy: 0.9112 - learning_rate: 5.0000e-04
## Epoch 148/500
## 90/90 - 0s - 1ms/step - loss: 0.0768 - sparse_categorical_accuracy: 0.9726 - val_loss: 0.1223 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 5.0000e-04
## Epoch 149/500
## 90/90 - 0s - 1ms/step - loss: 0.0664 - sparse_categorical_accuracy: 0.9792 - val_loss: 0.3194 - val_sparse_categorical_accuracy: 0.8821 - learning_rate: 5.0000e-04
## Epoch 150/500
## 90/90 - 0s - 1ms/step - loss: 0.0724 - sparse_categorical_accuracy: 0.9736 - val_loss: 0.1903 - val_sparse_categorical_accuracy: 0.9320 - learning_rate: 5.0000e-04
## Epoch 151/500
## 90/90 - 0s - 1ms/step - loss: 0.0651 - sparse_categorical_accuracy: 0.9795 - val_loss: 0.1087 - val_sparse_categorical_accuracy: 0.9542 - learning_rate: 2.5000e-04
## Epoch 152/500
## 90/90 - 0s - 2ms/step - loss: 0.0671 - sparse_categorical_accuracy: 0.9771 - val_loss: 0.1080 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 2.5000e-04
## Epoch 153/500
## 90/90 - 0s - 1ms/step - loss: 0.0628 - sparse_categorical_accuracy: 0.9799 - val_loss: 0.1053 - val_sparse_categorical_accuracy: 0.9584 - learning_rate: 2.5000e-04
## Epoch 154/500
## 90/90 - 0s - 1ms/step - loss: 0.0617 - sparse_categorical_accuracy: 0.9792 - val_loss: 0.1080 - val_sparse_categorical_accuracy: 0.9584 - learning_rate: 2.5000e-04
## Epoch 155/500
## 90/90 - 0s - 1ms/step - loss: 0.0638 - sparse_categorical_accuracy: 0.9785 - val_loss: 0.1102 - val_sparse_categorical_accuracy: 0.9612 - learning_rate: 2.5000e-04
## Epoch 156/500
## 90/90 - 0s - 1ms/step - loss: 0.0653 - sparse_categorical_accuracy: 0.9792 - val_loss: 0.1137 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 2.5000e-04
## Epoch 157/500
## 90/90 - 0s - 1ms/step - loss: 0.0643 - sparse_categorical_accuracy: 0.9743 - val_loss: 0.1324 - val_sparse_categorical_accuracy: 0.9542 - learning_rate: 2.5000e-04
## Epoch 158/500
## 90/90 - 0s - 1ms/step - loss: 0.0643 - sparse_categorical_accuracy: 0.9802 - val_loss: 0.1142 - val_sparse_categorical_accuracy: 0.9612 - learning_rate: 2.5000e-04
## Epoch 159/500
## 90/90 - 0s - 1ms/step - loss: 0.0634 - sparse_categorical_accuracy: 0.9767 - val_loss: 0.1093 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 2.5000e-04
## Epoch 160/500
## 90/90 - 0s - 2ms/step - loss: 0.0643 - sparse_categorical_accuracy: 0.9788 - val_loss: 0.1223 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 2.5000e-04
## Epoch 161/500
## 90/90 - 0s - 1ms/step - loss: 0.0641 - sparse_categorical_accuracy: 0.9771 - val_loss: 0.1612 - val_sparse_categorical_accuracy: 0.9376 - learning_rate: 2.5000e-04
## Epoch 162/500
## 90/90 - 0s - 1ms/step - loss: 0.0592 - sparse_categorical_accuracy: 0.9806 - val_loss: 0.1233 - val_sparse_categorical_accuracy: 0.9612 - learning_rate: 2.5000e-04
## Epoch 163/500
## 90/90 - 0s - 1ms/step - loss: 0.0564 - sparse_categorical_accuracy: 0.9823 - val_loss: 0.1099 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 2.5000e-04
## Epoch 164/500
## 90/90 - 0s - 1ms/step - loss: 0.0606 - sparse_categorical_accuracy: 0.9837 - val_loss: 0.1090 - val_sparse_categorical_accuracy: 0.9612 - learning_rate: 2.5000e-04
## Epoch 165/500
## 90/90 - 0s - 2ms/step - loss: 0.0590 - sparse_categorical_accuracy: 0.9802 - val_loss: 0.1163 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 2.5000e-04
## Epoch 166/500
## 90/90 - 0s - 1ms/step - loss: 0.0589 - sparse_categorical_accuracy: 0.9813 - val_loss: 0.1111 - val_sparse_categorical_accuracy: 0.9612 - learning_rate: 2.5000e-04
## Epoch 167/500
## 90/90 - 0s - 1ms/step - loss: 0.0588 - sparse_categorical_accuracy: 0.9802 - val_loss: 0.1034 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 2.5000e-04
## Epoch 168/500
## 90/90 - 0s - 1ms/step - loss: 0.0719 - sparse_categorical_accuracy: 0.9760 - val_loss: 0.1855 - val_sparse_categorical_accuracy: 0.9279 - learning_rate: 2.5000e-04
## Epoch 169/500
## 90/90 - 0s - 1ms/step - loss: 0.0603 - sparse_categorical_accuracy: 0.9795 - val_loss: 0.1147 - val_sparse_categorical_accuracy: 0.9570 - learning_rate: 2.5000e-04
## Epoch 170/500
## 90/90 - 0s - 1ms/step - loss: 0.0617 - sparse_categorical_accuracy: 0.9823 - val_loss: 0.1324 - val_sparse_categorical_accuracy: 0.9487 - learning_rate: 2.5000e-04
## Epoch 171/500
## 90/90 - 0s - 1ms/step - loss: 0.0549 - sparse_categorical_accuracy: 0.9816 - val_loss: 0.1115 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 1.2500e-04
## Epoch 172/500
## 90/90 - 0s - 1ms/step - loss: 0.0570 - sparse_categorical_accuracy: 0.9823 - val_loss: 0.1036 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 1.2500e-04
## Epoch 173/500
## 90/90 - 0s - 1ms/step - loss: 0.0563 - sparse_categorical_accuracy: 0.9823 - val_loss: 0.1378 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 1.2500e-04
## Epoch 174/500
## 90/90 - 0s - 1ms/step - loss: 0.0565 - sparse_categorical_accuracy: 0.9830 - val_loss: 0.1111 - val_sparse_categorical_accuracy: 0.9542 - learning_rate: 1.2500e-04
## Epoch 175/500
## 90/90 - 0s - 1ms/step - loss: 0.0573 - sparse_categorical_accuracy: 0.9819 - val_loss: 0.1083 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 1.2500e-04
## Epoch 176/500
## 90/90 - 0s - 2ms/step - loss: 0.0559 - sparse_categorical_accuracy: 0.9816 - val_loss: 0.1067 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 1.2500e-04
## Epoch 177/500
## 90/90 - 0s - 2ms/step - loss: 0.0567 - sparse_categorical_accuracy: 0.9844 - val_loss: 0.1050 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 1.2500e-04
## Epoch 178/500
## 90/90 - 0s - 2ms/step - loss: 0.0529 - sparse_categorical_accuracy: 0.9851 - val_loss: 0.1109 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 1.2500e-04
## Epoch 179/500
## 90/90 - 0s - 1ms/step - loss: 0.0542 - sparse_categorical_accuracy: 0.9826 - val_loss: 0.1144 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 1.2500e-04
## Epoch 180/500
## 90/90 - 0s - 1ms/step - loss: 0.0546 - sparse_categorical_accuracy: 0.9823 - val_loss: 0.1281 - val_sparse_categorical_accuracy: 0.9584 - learning_rate: 1.2500e-04
## Epoch 180: early stoppingEvaluate model on test data
model <- load_model("best_model.keras")
results <- model |> evaluate(x_test, y_test)## 42/42 - 0s - 11ms/step - loss: 0.1007 - sparse_categorical_accuracy: 0.9652
str(results)## List of 2
## $ loss : num 0.101
## $ sparse_categorical_accuracy: num 0.965
cat(
"Test accuracy: ", results$sparse_categorical_accuracy, "\n",
"Test loss: ", results$loss, "\n",
sep = ""
)## Test accuracy: 0.9651515
## Test loss: 0.1007335Plot the model’s training history
plot(history)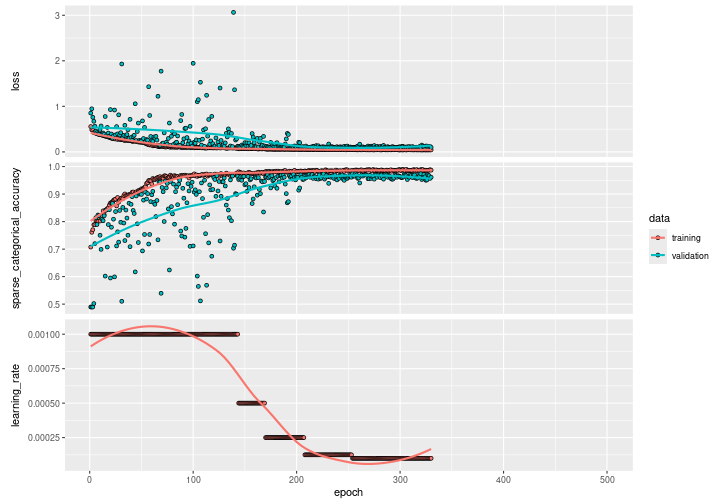
Plot just the training and validation accuracy:
plot(history, metric = "sparse_categorical_accuracy") +
# scale x axis to actual number of epochs run before early stopping
ggplot2::xlim(0, length(history$metrics$loss))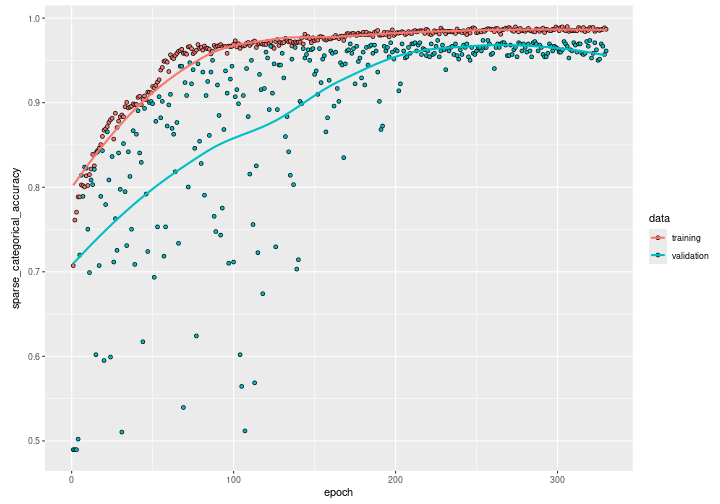
We can see how the training accuracy reaches almost 0.95 after 100 epochs. However, by observing the validation accuracy we can see how the network still needs training until it reaches almost 0.97 for both the validation and the training accuracy after 200 epochs. Beyond the 200th epoch, if we continue on training, the validation accuracy will start decreasing while the training accuracy will continue on increasing: the model starts overfitting.