Overview
The reticulate package includes a Python engine for R Markdown that enables easy interoperability between Python and R chunks.
Python chunks behave very similar to R chunks (including graphical output from matplotlib) and the two languages have full access each other’s objects. Built in conversion for many Python object types is provided, including NumPy arrays and Pandas data frames.
If you are using knitr version 1.18 or higher, then the reticulate Python engine will be enabled by default whenever reticulate is installed and no further setup is required. If you are running an earlier version of knitr or want to disable the use of the reticulate engine see the Engine Setup section below.
Python Version
By default, reticulate uses the version of Python found on your
PATH (i.e. Sys.which("python")). If you want
to use an alternate version you should add one of the
use_python() family of functions to your R Markdown setup
chunk, for example:

See the article on Python Version Configuration for additional details on configuring Python versions (including the use of conda or virtualenv environments).
Python Chunks
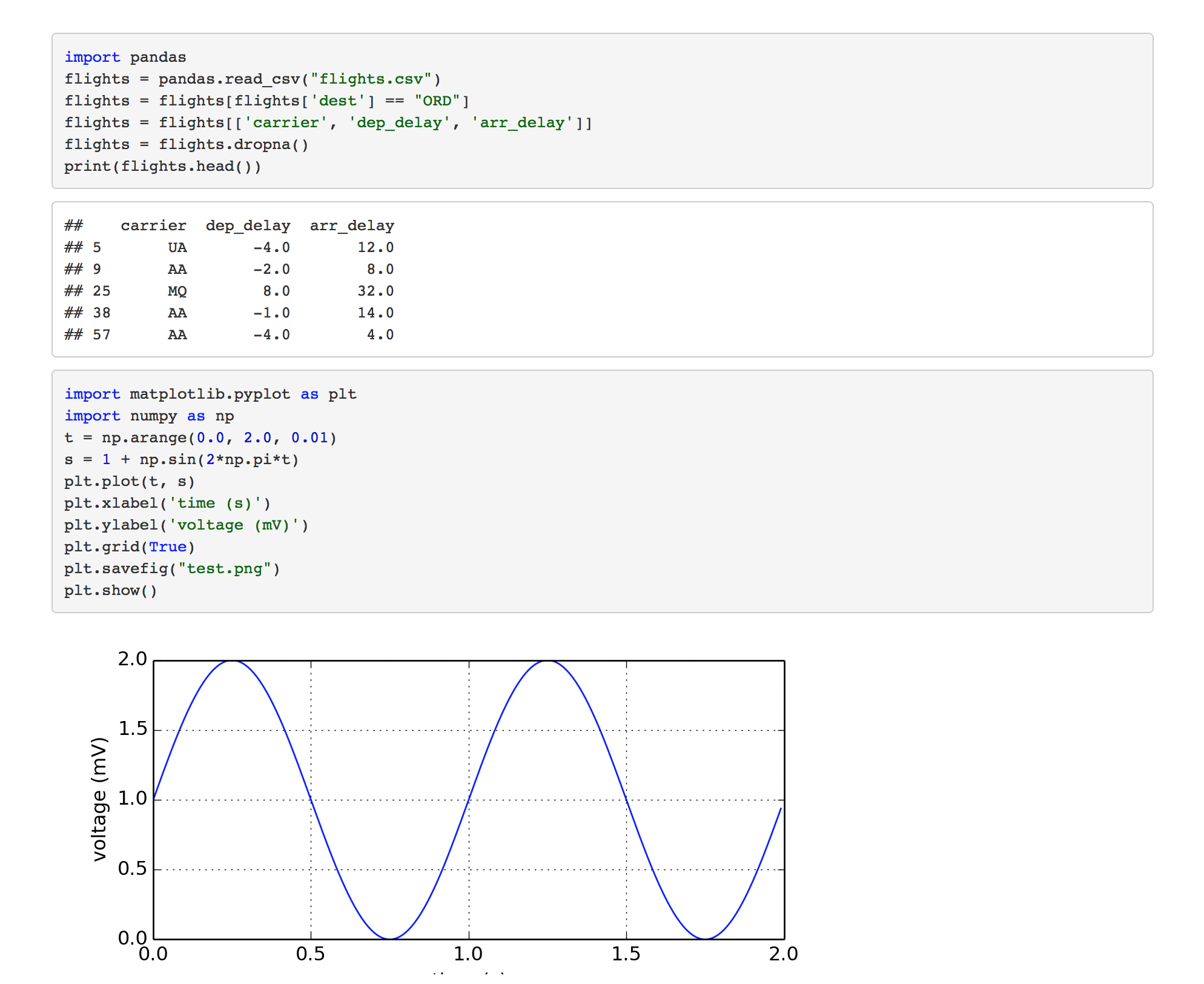
Python code chunks work exactly like R code chunks: Python code is executed and any print or graphical (matplotlib) output is included within the document.
Python chunks all execute within a single Python session so have
access to all objects created in previous chunks. Chunk options like
echo, include, etc. all work as expected.
Here’s an R Markdown document that demonstrates this:
RStudio v1.2 or greater for reticulate IDE support.
Calling Python from R
All objects created within Python chunks are available to R using the
py object exported by the reticulate package. For example,
the following code demonstrates reading and filtering a CSV file using
Pandas then plotting the resulting data frame using ggplot2:

See the Calling Python from R article for additional details on how to interact with Python types from within R