Draft a starter pointblank validation .R/.Rmd file with a data table
Source:R/draft_validation.R
draft_validation.RdGenerate a draft validation plan in a new .R or .Rmd file using an input data table. Using this workflow, the data table will be scanned to learn about its column data and a set of starter validation steps (constituting a validation plan) will be written. It's best to use a data extract that contains at least 1000 rows and is relatively free of spurious data.
Once in the file, it's possible to tweak the validation steps to better fit
the expectations to the particular domain. While column inference is used to
generate reasonable validation plans, it is difficult to infer the acceptable
values without domain expertise. However, using draft_validation() could
get you started on floor 10 of tackling data quality issues and is in any
case better than starting with an empty code editor view.
Usage
draft_validation(
tbl,
tbl_name = NULL,
filename = tbl_name,
path = NULL,
lang = NULL,
output_type = c("R", "Rmd"),
add_comments = TRUE,
overwrite = FALSE,
quiet = FALSE
)Arguments
- tbl
A data table
obj:<tbl_*>// requiredThe input table. This can be a data frame, tibble, a
tbl_dbiobject, or atbl_sparkobject.- tbl_name
A table name
scalar<character>// default:NULL(optional)A optional name to assign to the input table object. If no value is provided, a name will be generated based on whatever information is available. This table name will be displayed in the header area of the agent report generated by printing the agent or calling
get_agent_report().- filename
File name
scalar<character>// default:tbl_nameAn optional name for the .R or .Rmd file. This should be a name without an extension. By default, this is taken from the
tbl_namebut if nothing is supplied for that, the name will contain the text"draft_validation_"followed by the current date and time.- path
File path
scalar<character>// default:NULL(optional)A path can be specified here if there shouldn't be an attempt to place the generated file in the working directory.
- lang
Commenting language
scalar<character>// default:NULL(optional)The language to use when creating comments for the automatically- generated validation steps. By default,
NULLwill create English ("en") text. Other options include French ("fr"), German ("de"), Italian ("it"), Spanish ("es"), Portuguese ("pt"), Turkish ("tr"), Chinese ("zh"), Russian ("ru"), Polish ("pl"), Danish ("da"), Swedish ("sv"), and Dutch ("nl").- output_type
The output file type
singl-kw:[R|Rmd]// default:"R"An option for choosing what type of output should be generated. By default, this is an .R script (
"R") but this could alternatively be an R Markdown document ("Rmd").- add_comments
Add comments to the generated validation plan
scalar<logical>// default:TRUEShould there be comments that explain the features of the validation plan in the generated document?
- overwrite
Overwrite a previous file of the same name
scalar<logical>// default:FALSEShould a file of the same name be overwritten?
- quiet
Inform (or not) upon file writing
scalar<logical>// default:FALSEShould the function not inform when the file is written?
Supported Input Tables
The types of data tables that are officially supported are:
data frames (
data.frame) and tibbles (tbl_df)Spark DataFrames (
tbl_spark)the following database tables (
tbl_dbi):PostgreSQL tables (using the
RPostgres::Postgres()as driver)MySQL tables (with
RMySQL::MySQL())Microsoft SQL Server tables (via odbc)
BigQuery tables (using
bigrquery::bigquery())DuckDB tables (through
duckdb::duckdb())SQLite (with
RSQLite::SQLite())
Other database tables may work to varying degrees but they haven't been formally tested (so be mindful of this when using unsupported backends with pointblank).
Examples
Let's draft a validation plan for the dplyr::storms dataset.
dplyr::storms
#> # A tibble: 19,537 x 13
#> name year month day hour lat long status category wind pressure
#> <chr> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <fct> <dbl> <int> <int>
#> 1 Amy 1975 6 27 0 27.5 -79 tropical d~ NA 25 1013
#> 2 Amy 1975 6 27 6 28.5 -79 tropical d~ NA 25 1013
#> 3 Amy 1975 6 27 12 29.5 -79 tropical d~ NA 25 1013
#> 4 Amy 1975 6 27 18 30.5 -79 tropical d~ NA 25 1013
#> 5 Amy 1975 6 28 0 31.5 -78.8 tropical d~ NA 25 1012
#> 6 Amy 1975 6 28 6 32.4 -78.7 tropical d~ NA 25 1012
#> 7 Amy 1975 6 28 12 33.3 -78 tropical d~ NA 25 1011
#> 8 Amy 1975 6 28 18 34 -77 tropical d~ NA 30 1006
#> 9 Amy 1975 6 29 0 34.4 -75.8 tropical s~ NA 35 1004
#> 10 Amy 1975 6 29 6 34 -74.8 tropical s~ NA 40 1002
#> # i 19,527 more rows
#> # i 2 more variables: tropicalstorm_force_diameter <int>,
#> # hurricane_force_diameter <int>The draft_validation() function creates an .R file by default. Using just
the defaults with dplyr::storms will yield the "dplyr__storms.R" file
in the working directory. Here are the contents of the file:
library(pointblank)
agent <-
create_agent(
tbl = ~ dplyr::storms,
actions = action_levels(
warn_at = 0.05,
stop_at = 0.10
),
tbl_name = "dplyr::storms",
label = "Validation plan generated by `draft_validation()`."
) %>%
# Expect that column `name` is of type: character
col_is_character(
columns = name
) %>%
# Expect that column `year` is of type: numeric
col_is_numeric(
columns = year
) %>%
# Expect that values in `year` should be between `1975` and `2020`
col_vals_between(
columns = year,
left = 1975,
right = 2020
) %>%
# Expect that column `month` is of type: numeric
col_is_numeric(
columns = month
) %>%
# Expect that values in `month` should be between `1` and `12`
col_vals_between(
columns = month,
left = 1,
right = 12
) %>%
# Expect that column `day` is of type: integer
col_is_integer(
columns = day
) %>%
# Expect that values in `day` should be between `1` and `31`
col_vals_between(
columns = day,
left = 1,
right = 31
) %>%
# Expect that column `hour` is of type: numeric
col_is_numeric(
columns = hour
) %>%
# Expect that values in `hour` should be between `0` and `23`
col_vals_between(
columns = hour,
left = 0,
right = 23
) %>%
# Expect that column `lat` is of type: numeric
col_is_numeric(
columns = lat
) %>%
# Expect that values in `lat` should be between `-90` and `90`
col_vals_between(
columns = lat,
left = -90,
right = 90
) %>%
# Expect that column `long` is of type: numeric
col_is_numeric(
columns = long
) %>%
# Expect that values in `long` should be between `-180` and `180`
col_vals_between(
columns = long,
left = -180,
right = 180
) %>%
# Expect that column `status` is of type: character
col_is_character(
columns = status
) %>%
# Expect that column `category` is of type: factor
col_is_factor(
columns = category
) %>%
# Expect that column `wind` is of type: integer
col_is_integer(
columns = wind
) %>%
# Expect that values in `wind` should be between `10` and `160`
col_vals_between(
columns = wind,
left = 10,
right = 160
) %>%
# Expect that column `pressure` is of type: integer
col_is_integer(
columns = pressure
) %>%
# Expect that values in `pressure` should be between `882` and `1022`
col_vals_between(
columns = pressure,
left = 882,
right = 1022
) %>%
# Expect that column `tropicalstorm_force_diameter` is of type: integer
col_is_integer(
columns = tropicalstorm_force_diameter
) %>%
# Expect that values in `tropicalstorm_force_diameter` should be between
# `0` and `870`
col_vals_between(
columns = tropicalstorm_force_diameter,
left = 0,
right = 870,
na_pass = TRUE
) %>%
# Expect that column `hurricane_force_diameter` is of type: integer
col_is_integer(
columns = hurricane_force_diameter
) %>%
# Expect that values in `hurricane_force_diameter` should be between
# `0` and `300`
col_vals_between(
columns = hurricane_force_diameter,
left = 0,
right = 300,
na_pass = TRUE
) %>%
# Expect entirely distinct rows across all columns
rows_distinct() %>%
# Expect that column schemas match
col_schema_match(
schema = col_schema(
name = "character",
year = "numeric",
month = "numeric",
day = "integer",
hour = "numeric",
lat = "numeric",
long = "numeric",
status = "character",
category = c("ordered", "factor"),
wind = "integer",
pressure = "integer",
tropicalstorm_force_diameter = "integer",
hurricane_force_diameter = "integer"
)
) %>%
interrogate()
agentThis is runnable as is, and the promise is that the interrogation should produce no failing test units. After execution, we get the following validation report:
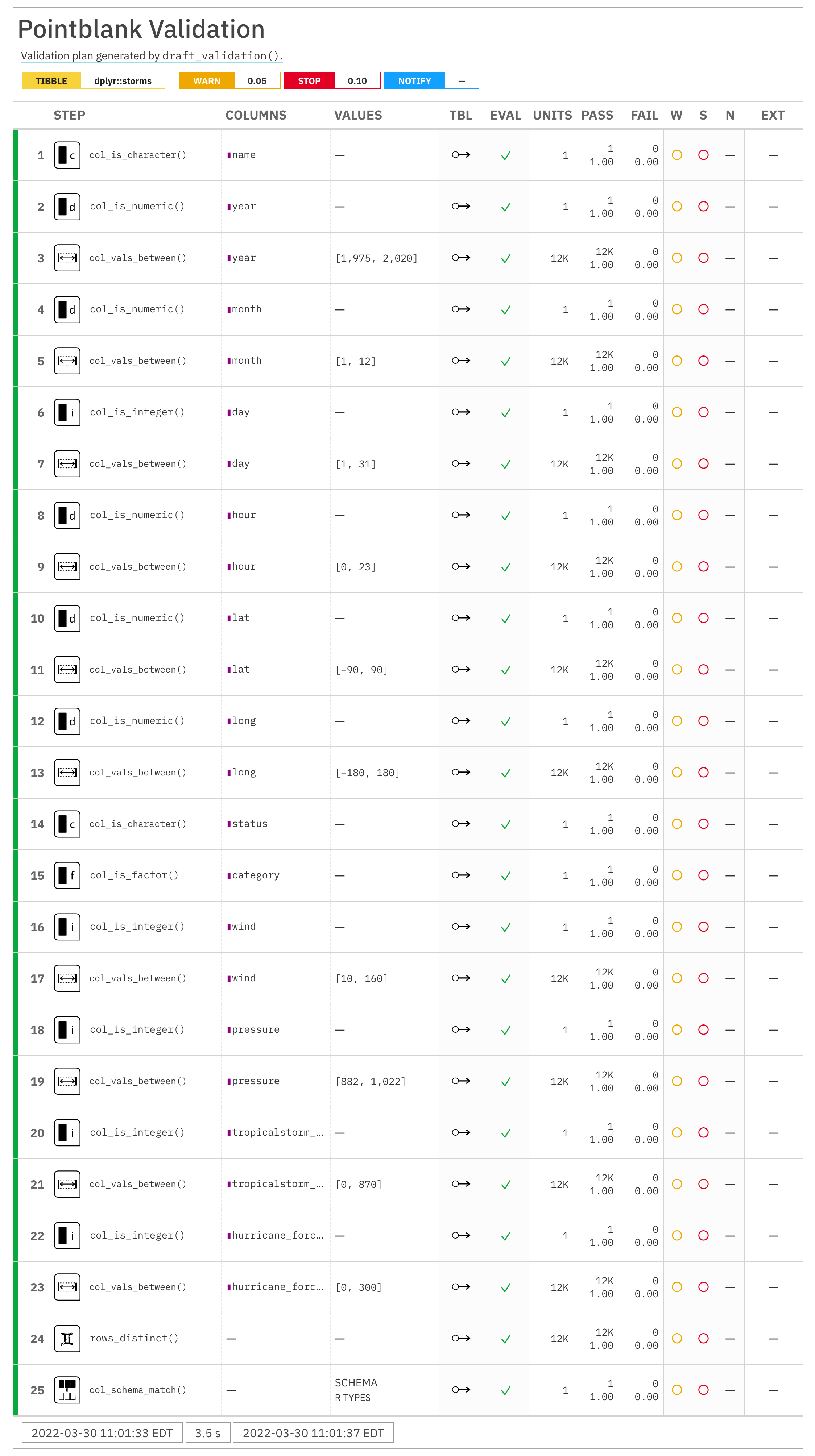
All of the expressions in the resulting file constitute just a rough
approximation of what a validation plan should be for a dataset. Certainly,
the value ranges in the emitted col_vals_between() may not be realistic for
the wind column and may require some modification (the provided left and
right values are just the limits of the provided data). However, note that
the lat and long (latitude and longitude) columns have acceptable ranges
(providing the limits of valid lat/lon values). This is thanks to
pointblank's column inference routines, which is able to understand what
certain columns contain.
For an evolving dataset that will experience changes (either in the form of revised data and addition/deletion of rows or columns), the emitted validation will serve as a good first step and changes can more easily be made since there is a foundation to build from.
See also
Other Planning and Prep:
action_levels(),
create_agent(),
create_informant(),
db_tbl(),
file_tbl(),
scan_data(),
tbl_get(),
tbl_source(),
tbl_store(),
validate_rmd()