The create_agent() function creates an agent object, which is used in a
data quality reporting workflow. The overall aim of this workflow is to
generate useful reporting information for assessing the level of data quality
for the target table. We can supply as many validation functions as the user
wishes to write, thereby increasing the level of validation coverage for that
table. The agent assigned by the create_agent() call takes validation
functions (e.g., col_vals_between(), rows_distinct(), etc.), which
translate to discrete validation steps (each one is numbered and will later
provide its own set of results). This process is known as developing a
validation plan.
The validation functions, when called on an agent, are merely instructions
up to the point the interrogate() function is called. That kicks off the
process of the agent acting on the validation plan and getting results
for each step. Once the interrogation process is complete, we can say that
the agent has intel. Calling the agent itself will result in a reporting
table. This reporting of the interrogation can also be accessed with the
get_agent_report() function, where there are more reporting options.
Usage
create_agent(
tbl = NULL,
tbl_name = NULL,
label = NULL,
actions = NULL,
end_fns = NULL,
embed_report = FALSE,
lang = NULL,
locale = NULL,
read_fn = NULL
)Arguments
- tbl
Table or expression for reading in one
obj:<tbl_*>|<tbl reading expression>// requiredThe input table. This can be a data frame, a tibble, a
tbl_dbiobject, or atbl_sparkobject. Alternatively, an expression can be supplied to serve as instructions on how to retrieve the target table at interrogation-time. There are two ways to specify an association to a target table: (1) as a table-prep formula, which is a right-hand side (RHS) formula expression (e.g.,~ { <tbl reading code>}), or (2) as a function (e.g.,function() { <tbl reading code>}).- tbl_name
A table name
scalar<character>// default:NULL(optional)A optional name to assign to the input table object. If no value is provided, a name will be generated based on whatever information is available. This table name will be displayed in the header area of the agent report generated by printing the agent or calling
get_agent_report().- label
An optional label for the validation plan
scalar<character>// default:NULL(optional)An optional label for the validation plan. If no value is provided, a label will be generated based on the current system time. Markdown can be used here to make the label more visually appealing (it will appear in the header area of the agent report).
- actions
Default thresholds and actions for different states
obj:<action_levels>// default:NULL(optional)A option to include a list with threshold levels so that all validation steps can react accordingly when exceeding the set levels. This is to be created with the
action_levels()helper function. Should an action levels list be used for a specific validation step, the default set specified here will be overridden.- end_fns
Functions to execute after interrogation
list// default:NULL(optional)A list of expressions that should be invoked at the end of an interrogation. Each expression should be in the form of a one-sided R formula, so overall this construction should be used:
end_fns = list(~ <R statements>, ~ <R statements>, ...). An example of a function included in pointblank that can be sensibly used here isemail_blast(), which sends an email of the validation report (based on a sending condition).- embed_report
Embed the validation report into agent object?
scalar<logical>// default:FALSEAn option to embed a gt-based validation report into the
ptblank_agentobject. IfFALSEthen the table object will be not generated and available with the agent upon returning from the interrogation.- lang
Reporting language
scalar<character>// default:NULL(optional)The language to use for automatic creation of briefs (short descriptions for each validation step) and for the agent report (a summary table that provides the validation plan and the results from the interrogation. By default,
NULLwill create English ("en") text. Other options include French ("fr"), German ("de"), Italian ("it"), Spanish ("es"), Portuguese ("pt"), Turkish ("tr"), Chinese ("zh"), Russian ("ru"), Polish ("pl"), Danish ("da"), Swedish ("sv"), and Dutch ("nl").- locale
Locale for value formatting within reports
scalar<character>// default:NULL(optional)An optional locale ID to use for formatting values in the agent report summary table according the locale's rules. Examples include
"en_US"for English (United States) and"fr_FR"for French (France); more simply, this can be a language identifier without a country designation, like "es" for Spanish (Spain, same as"es_ES").- read_fn
Deprecated Table reading function
function// default:NULL(optional)The
read_fnargument is deprecated. Instead, supply a table-prep formula or function totbl.
Supported Input Tables
The types of data tables that are officially supported are:
data frames (
data.frame) and tibbles (tbl_df)Spark DataFrames (
tbl_spark)the following database tables (
tbl_dbi):PostgreSQL tables (using the
RPostgres::Postgres()as driver)MySQL tables (with
RMySQL::MySQL())Microsoft SQL Server tables (via odbc)
BigQuery tables (using
bigrquery::bigquery())DuckDB tables (through
duckdb::duckdb())SQLite (with
RSQLite::SQLite())
Other database tables may work to varying degrees but they haven't been formally tested (so be mindful of this when using unsupported backends with pointblank).
The Use of an Agent for Validation Is Just One Option of Several
There are a few validation workflows and using an agent is the one that provides the most options. It is probably the best choice for assessing the state of data quality since it yields detailed reporting, has options for further exploration of root causes, and allows for granular definition of actions to be taken based on the severity of validation failures (e.g., emailing, logging, etc.).
Different situations, however, call for different validation workflows. You use validation functions (the same ones you would with an agent) directly on the data. This acts as a sort of data filter in that the input table will become output data (without modification), but there may be warnings, errors, or other side effects that you can define if validation fails. Basically, instead of this
create_agent(tbl = small_table) %>% rows_distinct() %>% interrogate()you would use this:
small_table %>% rows_distinct()This results in an error (with the default failure threshold settings), displaying the reason for the error in the console. Notably, the data is not passed though.
We can use variants of the validation functions, the test (test_*()) and
expectation (expect_*()) versions, directly on the data for different
workflows. The first returns to us a logical value. So this
small_table %>% test_rows_distinct()returns FALSE instead of an error.
In a unit testing scenario, we can use expectation functions exactly as we
would with testthat's library of expect_*() functions:
small_table %>% expect_rows_distinct()This test of small_table would be counted as a failure.
The Agent Report
While printing an agent (a ptblank_agent object) will display its
reporting in the Viewer, we can alternatively use the get_agent_report() to
take advantage of other options (e.g., overriding the language, modifying the
arrangement of report rows, etc.), and to return the report as independent
objects. For example, with the display_table = TRUE option (the default),
get_agent_report() will return a ptblank_agent_report object. If
display_table is set to FALSE, we'll get a data frame back instead.
Exporting the report as standalone HTML file can be accomplished by using the
export_report() function. This function can accept either the
ptblank_agent object or the ptblank_agent_report as input. Each HTML
document written to disk in this way is self-contained and easily viewable in
a web browser.
Data Products Obtained from an Agent
A very detailed list object, known as an x-list, can be obtained by using the
get_agent_x_list() function on the agent. This font of information can be
taken as a whole, or, broken down by the step number (with the i argument).
Sometimes it is useful to see which rows were the failing ones. By using the
get_data_extracts() function on the agent, we either get a list of
tibbles (for those steps that have data extracts) or one tibble if the
validation step is specified with the i argument.
The target data can be split into pieces that represent the 'pass' and 'fail'
portions with the get_sundered_data() function. A primary requirement is an
agent that has had interrogate() called on it. In addition, the validation
steps considered for this data splitting need to be those that operate on
values down a column (e.g., the col_vals_*() functions or conjointly()).
With these in-consideration validation steps, rows with no failing test units
across all validation steps comprise the 'pass' data piece, and rows with at
least one failing test unit across the same series of validations constitute
the 'fail' piece.
If we just need to know whether all validations completely passed (i.e., all
steps had no failing test units), the all_passed() function could be used
on the agent. However, in practice, it's not often the case that all data
validation steps are free from any failing units.
YAML
A pointblank agent can be written to YAML with yaml_write() and the
resulting YAML can be used to regenerate an agent (with yaml_read_agent())
or interrogate the target table (via yaml_agent_interrogate()). Here is an
example of how a complex call of create_agent() is expressed in R code and
in the corresponding YAML representation.
R statement:
create_agent(
tbl = ~ small_table,
tbl_name = "small_table",
label = "An example.",
actions = action_levels(
warn_at = 0.10,
stop_at = 0.25,
notify_at = 0.35,
fns = list(notify = ~ email_blast(
x,
to = "joe_public@example.com",
from = "pb_notif@example.com",
msg_subject = "Table Validation",
credentials = blastula::creds_key(
id = "smtp2go"
)
))
),
end_fns = list(
~ beepr::beep(2),
~ Sys.sleep(1)
),
embed_report = TRUE,
lang = "fr",
locale = "fr_CA"
)YAML representation:
type: agent
tbl: ~small_table
tbl_name: small_table
label: An example.
lang: fr
locale: fr_CA
actions:
warn_fraction: 0.1
stop_fraction: 0.25
notify_fraction: 0.35
fns:
notify: ~email_blast(x, to = "joe_public@example.com",
from = "pb_notif@example.com",
msg_subject = "Table Validation",
credentials = blastula::creds_key(id = "smtp2go"))
end_fns:
- ~beepr::beep(2)
- ~Sys.sleep(1)
embed_report: true
steps: []In practice, this YAML file will be shorter since arguments with default
values won't be written to YAML when using yaml_write() (though it is
acceptable to include them with their default when generating the YAML by
other means). The only requirement for writing the YAML representation of an
agent is having tbl specified as table-prep formula.
What typically follows this chunk of YAML is a steps part, and that
corresponds to the addition of validation steps via validation functions.
Help articles for each validation function have a YAML section that
describes how a given validation function is translated to YAML.
Should you need to preview the transformation of an agent to YAML (without
any committing anything to disk), use the yaml_agent_string() function. If
you already have a .yml file that holds an agent, you can get a glimpse
of the R expressions that are used to regenerate that agent with
yaml_agent_show_exprs().
Writing an Agent to Disk
An agent object can be written to disk with the x_write_disk() function.
This can be useful for keeping a history of validations and generating views
of data quality over time. Agents are stored in the serialized RDS format and
can be easily retrieved with the x_read_disk() function.
It's recommended that table-prep formulas are supplied to the tbl
argument of create_agent(). In this way, when an agent is read from disk
through x_read_disk(), it can be reused to access the target table (which
may change, hence the need to use an expression for this).
Combining Several Agents in a multiagent Object
Multiple agent objects can be part of a multiagent object, and two
functions can be used for this: create_multiagent() and
read_disk_multiagent(). By gathering multiple agents that have performed
interrogations in the past, we can get a multiagent report showing how data
quality evolved over time. This use case is interesting for data quality
monitoring and management, and, the reporting (which can be customized with
get_multiagent_report()) is robust against changes in validation steps for
a given target table.
Examples
Creating an agent, adding a validation plan, and interrogating
Let's walk through a data quality analysis of an extremely small table. It's
actually called small_table and we can find it as a dataset in this
package.
small_table
#> # A tibble: 13 x 8
#> date_time date a b c d e f
#> <dttm> <date> <int> <chr> <dbl> <dbl> <lgl> <chr>
#> 1 2016-01-04 11:00:00 2016-01-04 2 1-bcd-345 3 3423. TRUE high
#> 2 2016-01-04 00:32:00 2016-01-04 3 5-egh-163 8 10000. TRUE low
#> 3 2016-01-05 13:32:00 2016-01-05 6 8-kdg-938 3 2343. TRUE high
#> 4 2016-01-06 17:23:00 2016-01-06 2 5-jdo-903 NA 3892. FALSE mid
#> 5 2016-01-09 12:36:00 2016-01-09 8 3-ldm-038 7 284. TRUE low
#> 6 2016-01-11 06:15:00 2016-01-11 4 2-dhe-923 4 3291. TRUE mid
#> 7 2016-01-15 18:46:00 2016-01-15 7 1-knw-093 3 843. TRUE high
#> 8 2016-01-17 11:27:00 2016-01-17 4 5-boe-639 2 1036. FALSE low
#> 9 2016-01-20 04:30:00 2016-01-20 3 5-bce-642 9 838. FALSE high
#> 10 2016-01-20 04:30:00 2016-01-20 3 5-bce-642 9 838. FALSE high
#> 11 2016-01-26 20:07:00 2016-01-26 4 2-dmx-010 7 834. TRUE low
#> 12 2016-01-28 02:51:00 2016-01-28 2 7-dmx-010 8 108. FALSE low
#> 13 2016-01-30 11:23:00 2016-01-30 1 3-dka-303 NA 2230. TRUE highWe ought to think about what's tolerable in terms of data quality so let's
designate proportional failure thresholds to the warn, stop, and notify
states using action_levels().
al <-
action_levels(
warn_at = 0.10,
stop_at = 0.25,
notify_at = 0.35
)Now create a pointblank agent object and give it the al object (which
serves as a default for all validation steps which can be overridden). The
static thresholds provided by al will make the reporting a bit more useful.
We also provide a target table and we'll use pointblank::small_table.
agent <-
create_agent(
tbl = pointblank::small_table,
tbl_name = "small_table",
label = "`create_agent()` example.",
actions = al
)Then, as with any agent object, we can add steps to the validation plan by
using as many validation functions as we want. then, we use interrogate()
to actually perform the validations and gather intel.
agent <-
agent %>%
col_exists(columns = c(date, date_time)) %>%
col_vals_regex(
columns = b,
regex = "[0-9]-[a-z]{3}-[0-9]{3}"
) %>%
rows_distinct() %>%
col_vals_gt(columns = d, value = 100) %>%
col_vals_lte(columns = c, value = 5) %>%
col_vals_between(
columns = c,
left = vars(a), right = vars(d),
na_pass = TRUE
) %>%
interrogate()The agent object can be printed to see the validation report in the
Viewer.
agent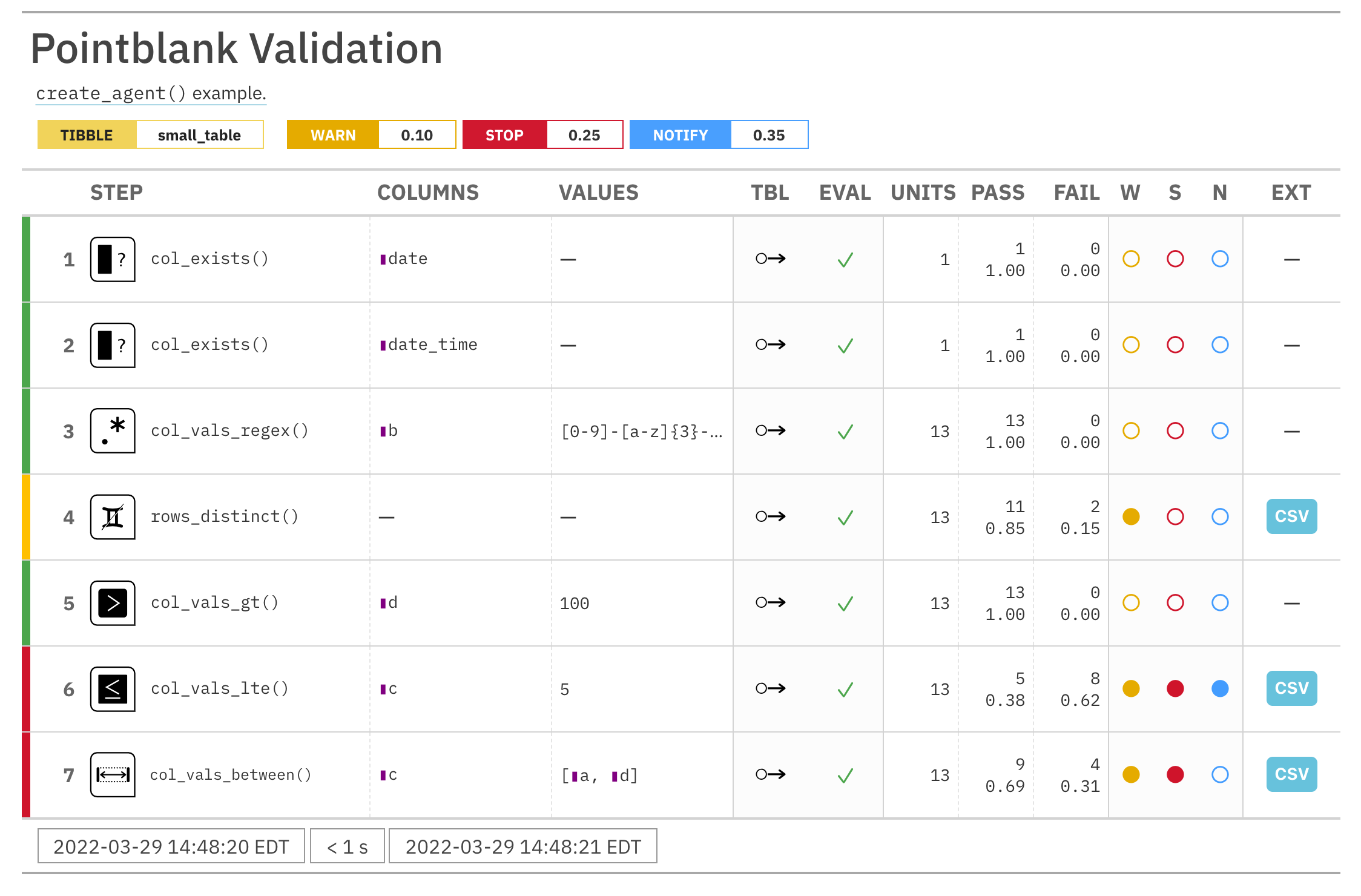
If we want to make use of more report display options, we can alternatively
use the get_agent_report() function.
report <-
get_agent_report(
agent = agent,
arrange_by = "severity",
title = "Validation of `small_table`"
)
report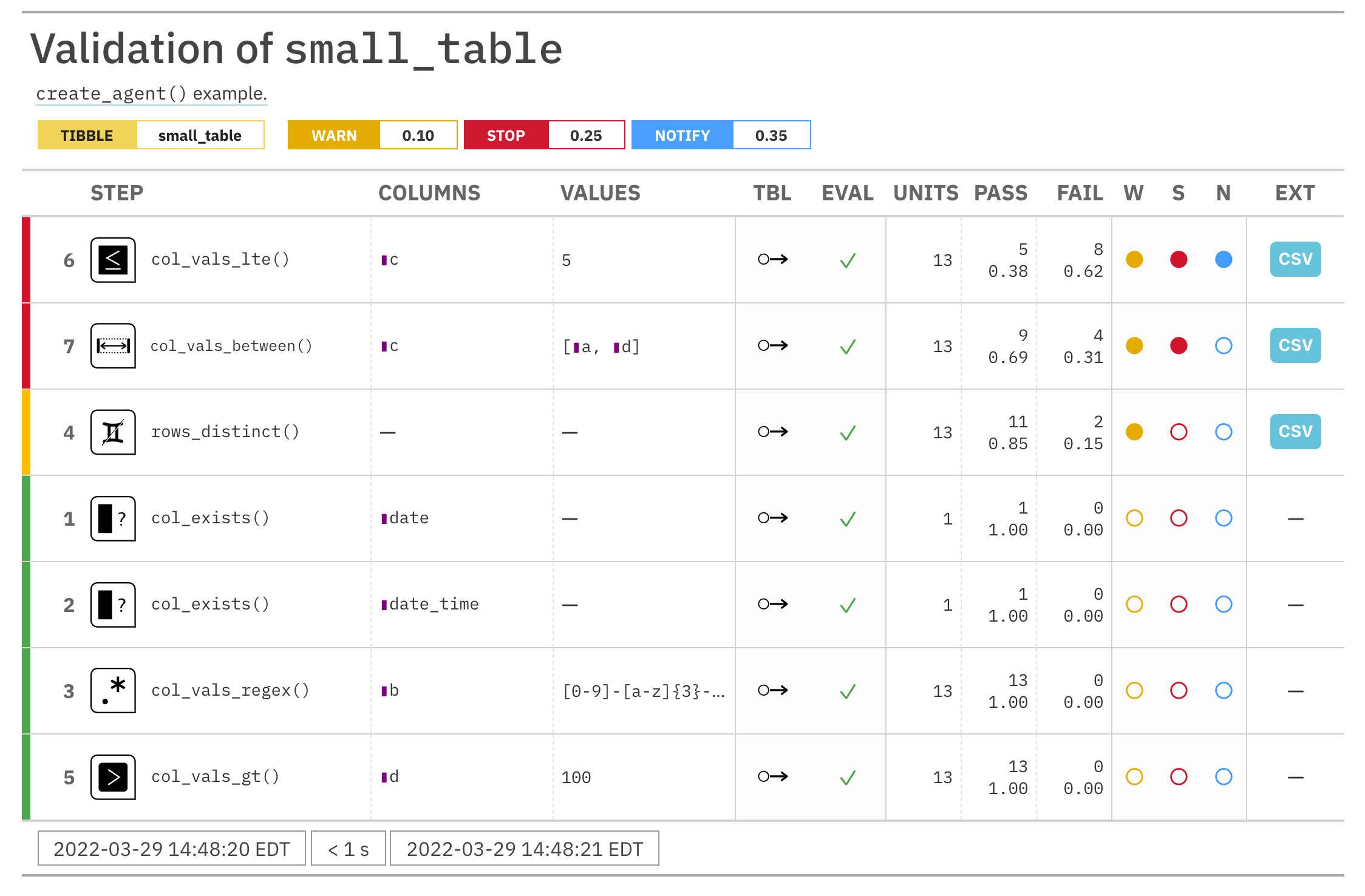
Post-interrogation operations
We can use the agent object with a variety of functions to get at more
of the information collected during interrogation.
We can see from the validation report that Step 4 (which used the
rows_distinct() validation function) had two test units, corresponding to
duplicated rows, that failed. We can see those rows with
get_data_extracts().
agent %>% get_data_extracts(i = 4)## # A tibble: 2 × 8
## date_time date a b c d e f
## <dttm> <date> <int> <chr> <dbl> <dbl> <lgl> <chr>
## 1 2016-01-20 04:30:00 2016-01-20 3 5-bce-6… 9 838. FALSE high
## 2 2016-01-20 04:30:00 2016-01-20 3 5-bce-6… 9 838. FALSE highWe can get an x-list for the entire validation process (7 steps), or, just
for the 4th step with get_agent_x_list().
xl_step_4 <- agent %>% get_agent_x_list(i = 4)And then we can peruse the different parts of the list. Let's get the fraction of test units that failed.
xl_step_4$f_failedAn x-list not specific to any step will have way more information and a
slightly different structure. See help(get_agent_x_list) for more info.
See also
Other Planning and Prep:
action_levels(),
create_informant(),
db_tbl(),
draft_validation(),
file_tbl(),
scan_data(),
tbl_get(),
tbl_source(),
tbl_store(),
validate_rmd()